")
In a world increasingly driven by real-time, contextual AI applications, Retrieval-Augmented Generation (RAG) has become foundational for enterprise-grade generative AI systems. At Deliqt, we’ve architected a robust and scalable RAG framework purpose-built for powering agentic AI experiences—where AI not only retrieves and summarizes information but takes meaningful actions based on it.
Here’s how we design, deploy, and evolve production-grade RAG systems that deliver both depth and agility.
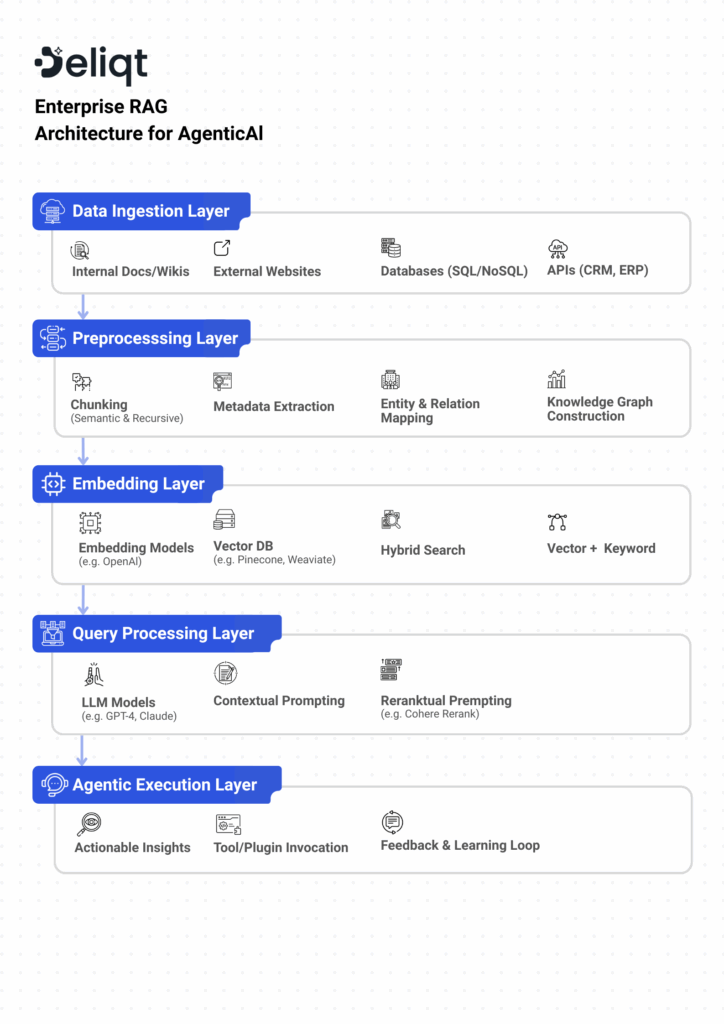
1. Foundation: Structured Data Gathering Across Sources
The quality of a RAG system is only as good as its source material. We start by pulling data from multiple enterprise systems including:
- Internal documentation and wikis
- Public websites
- Databases and CRM systems
- PDFs and regulatory filings
- Product manuals and structured JSON/CSV outputs
We ensure all data ingestion is versioned and access-controlled for enterprise compliance.
2. Smart Chunking: Beyond Plain Text Slicing
Instead of naive splitting, we employ semantic-aware chunking strategies like:
- Recursive Character Splitting with overlap
- Section-wise chunking for PDFs
- Metadata-preserving chunks for traceability
This ensures context is retained within each chunk, increasing retrieval relevance.
3. Knowledge Graph Layer: Injecting Structured Intelligence
Unlike traditional RAG pipelines, we construct a lightweight knowledge graph as part of preprocessing. Here’s how it works:
- We identify entities and relationships per chunk
- These are used to create a contextual map (graph)
- Each vector in the DB is linked to its graph relations
This allows the AI model to reason across entities—not just retrieve isolated facts.
4. Embedding & Storage: Optimized for Retrieval
We use domain-tuned embedding models (like OpenAI’s text-embedding-3-large or Cohere Embed v3) and store results in a vector database (e.g., Pinecone, Weaviate, or Qdrant).
Each vector is stored with:
The chunk content
Associated metadata (source, tags, security level)
Graph relations for contextual expansion
Collections are segmented to align with business domains—enabling collection-level routing.
5. Retrieval Pipeline: Precise, Relevant, and Fast
When a user query arrives:
- The query is decomposed into sub-queries using NLP-based chunking.
- Each sub-query performs vector search independently.
- Retrieved results are reranked based on semantic relevance.
- Top-ranked chunks (usually 3-5) are fed to the model, along with the original query.
We use hybrid retrieval—combining keyword and vector search for precision, especially with domain-specific queries.
6. Query Routing & Multi-Model Integration
In multi-domain or multi-LLM setups, we use semantic or logical routing to:
- Route to the most relevant vector collection
- Invoke the right LLM (e.g., GPT-4 for reasoning, Claude for summarization)
- Balance cost and performance
Routing improves both quality and system efficiency, especially at scale.
7. Feedback Loops & Observability: Closing the Loop
We use tools like LangSmith or LangFuse to monitor:
- Token usage
- Latency per response
- Embedding recall quality
- Human feedback (thumbs up/down, explicit corrections)
All feedback is stored and linked to the embedding chain to support continuous fine-tuning and regression testing.
8. Enterprise-Readiness: Governance, Security, and Compliance
No system is truly enterprise-grade without robust safeguards:
- Data governance: Versioned sources, document lineage
- Access control: Role-based filtering at retrieval time
- Audit logs: Every access and generation step is logged
- Encryption: In transit and at rest for all data
We also support SSO integrations and regulatory compliance workflows.
9. Caching & Optimization: Designed for Scale
For high-volume use cases or repeated queries, we use:
- Query-level caching at the embedding or LLM response level
- Chunk prefetching for anticipated queries
- LLM token usage optimization via prompt pruning and reranking
This reduces latency and cost dramatically—without compromising performance.
10. Agentic AI Integration: RAG + Actionability
We don’t stop at Q&A. Our RAG systems power agentic workflows—where responses can trigger:
- API calls
- Task creation
- Calendar booking
- CRM updates
Every retrieved piece of knowledge becomes a potential action trigger—which is where true agentic value begins.
The Deliqt Edge
What sets our RAG systems apart is not just how we retrieve—but how we combine:
- Semantic context from knowledge graphs
- Precision routing via collections and models
- Human feedback loops for improvement
- Operational observability for trust and control
All of this makes our architecture not just smart—but accountable, adaptive, and aligned to enterprise needs.
Want to see how our RAG system can work for your organization?
Let’s talk. Deliqt builds modular, scalable AI systems you can trust.